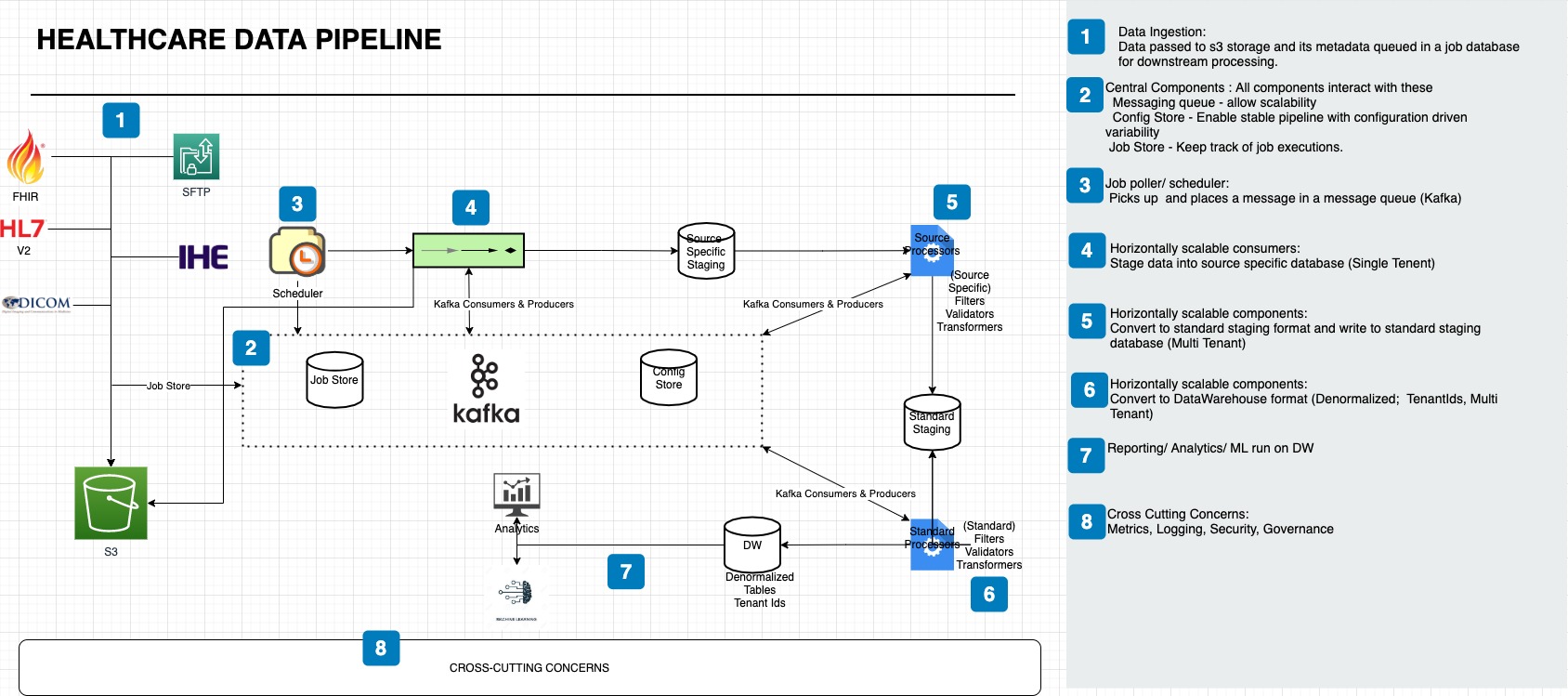
In this article lets abbreviate NoCode /low code drag & drop ETL tools as “d&d” for brevity.
There is no shortage of NoCode ETL advocates out there.In practice, I have found that while NoCode solutions can save you time and money, there are a few pitfalls you have to put up with.
In this article we will look at some limitations of this type of ETL.
I have seen several sales pitches made by ETL vendors where they blissfully drag and drop some ‘super’ connector that can handle a given data format / communication protocol. Some are even Vendor specific (SalesForce..etc). It seems impressive on the face of it. What..? we don’t have to code a http endpoint to send or receive the data? Wonderful..lets buy this now!!.
Usually this works in simple one-off use cases. But soon enough you find that the configuration options out of the box do not let you reuse the same component in some different situations.
Let’s compare the d&d components to code. Think of the configurations values that the d&d components have as fields in a class that are used to alter behavior. These configurations are supposed to allow customization right? So what is missing? Let’s see a few limitations of these tools.
Loss of Object Hierarchy & Abstraction
This is perhaps the most overlooked downside of using drag and drop etl tools.
Say you need to validate your data as it is being read. Simple, just create a d&d component with your validation rules.Now say you need to validate 2 domain objects, Users and Addresses. Now you need 2 different validator d&d components – UserValidator, AddressValidator.
Next, say each validator should send a notification to some system when validation rules are broken. Now you have to add (a) notification component(s) (even if its the same reusable component ) to each of your 2 validator components. See how the number of components is going up? Your d&d design area will get very cluttered very quickly.
An attempt to decouple these d&d components to reduce clutter results in a kind of GOTO flow with one flow referencing another separate flow. This becomes difficult to visually keep track of once you have several of these ‘jump-to’ flows. I contend that it is easier to follow class abstractions to their implementations (all good IDEs will do this easily) than it is to click through flows that reference other flows in complicated d&d design area
Now how can coding make this easier? Well you can have your Domain objects extend a common class. Say an abstract class called Validator. The notification method can be placed in the parent class or in a decorator class that wraps it. You don’t need to use N notifiers for N domain objects that you have in your system.
Another example here is if your validators need to do some standard steps before or after validation. These can go in the parent class rather than be duplicated in child classes. You really cant do this easily with d&d
You can easily see this is in effect comparing a 2D design to a 3D one, d&d tools force you to have all your functionality on the the same hierarchy level. Using classes allow you to abstract away common functionality and have less verbose code, easier to understand, less cluttered and faster to create and extend.
Limited Configuration based orchestration
In a real world data pipeline , often you need to read some configuration and apply different logic to transform data and sometimes in different order/sequences. For example in healthcare, based on a source of the data, you might need a different logic to match patient identities.
Say one patient match strategy is to call an external service and the another is to use an internal service. Using d&d you will need to drop as many components as there are strategies and maybe read the config and select which path to follow. If a 3rd strategy becomes necessary, you will have to edit the existing pipeline and add a new component. Modifying an existing pipeline will require a full round of testing. Also this can lead to a really cluttered d&d design area.
If using Code this design can be abstracted away behind a patient matching interface that has multiple implementations that are selected at runtime by only changing configuration. Adding a new strategy is as simple as adding 1 class and creating configuration to use it. This will need a limited testing effort. Also these strategies can use inheritance as noted in the 1st point above, to keep similar behavior in one class further reducing the clutter.
Learning Curve
One thing that becomes apparent once you start using d&d etl tools is that by trying to get away from code as it requires more skilled developers, you find that every tool becomes complicated once the business logic becomes complex.
As every etl tool has its own ‘philosophy’, it can take your analyst/developers a long time to figure out where all the tuning knobs are hidden and when to use them and in what combinations to apply them. So you end up just trading one type of complexity for another. I have seen etl tool setups that are so complex that they actually need a developer that can code to maintain them.
Rather than look to run from a coding solution, I would suggest to try get at-least one good architect/senior developer who will apply common design patterns to the ETL code.
Reusability
The good ETL tools usually provide a way to create reusable components (maplets in informatica, joblets in talend).
What I have observed in practice is that because of the ease of just dragging stuff onto the UI, or because of lack of proper design thinking (that would be more likely to happen if using code), most people end up not using these reusable components. As an example if theres need to standardize addresses, the same d&d component is created in multiple data pipelines say user addresses, company addresses, doctor addresses.
When a change is needed to the logic for standardizing addresses , in a d&d tool you end up with have several places to make the change.
If using code , It forces you to have some forethought about nature of classes to be used and I would imagine a single class to do address validation that is called from different pipelines would be the solution arrived at.
Testing
Testing d&d components is usually not as straight forward as it is for coded solutions. In the age of continuous integration, there is more emphasis on automated tests that run before deployment. There are more tools and frameworks for running these tests for , say a java/spring or c#/ .net solution than there are for d&d etl tools.
Some ETL tools like informatica will have functionality to create tests, but others like Snaplogic do not have a 1st class support for testing. Even when support for testing is built-in, I contend that coded tests are better for a few reasons. Coded Tests can make use of constructs like mocks to abstract away external dependencies. Coded Tests can make use of dependency injection to swap out implementations at runtime (Example , if the etl job calls a rest endpoint). Coded tests are less likely to be vendor specific & easier to migrate to new platforms.
Conclusion
In the end, whether to use a NoCode Drag& Drop ETL tool or to use code will depend on the nature of the job at hand.
Simple dataflows may be easily done in a no/low code etl tool. But in my experience in healthcare it is rarely the case that dataflows are that simple. At one of my previous jobs, we actually ended up just using the etl tool as an orchestration tool. The job responsibility was to call and schedule the run of complex stored procedures and coded applications.