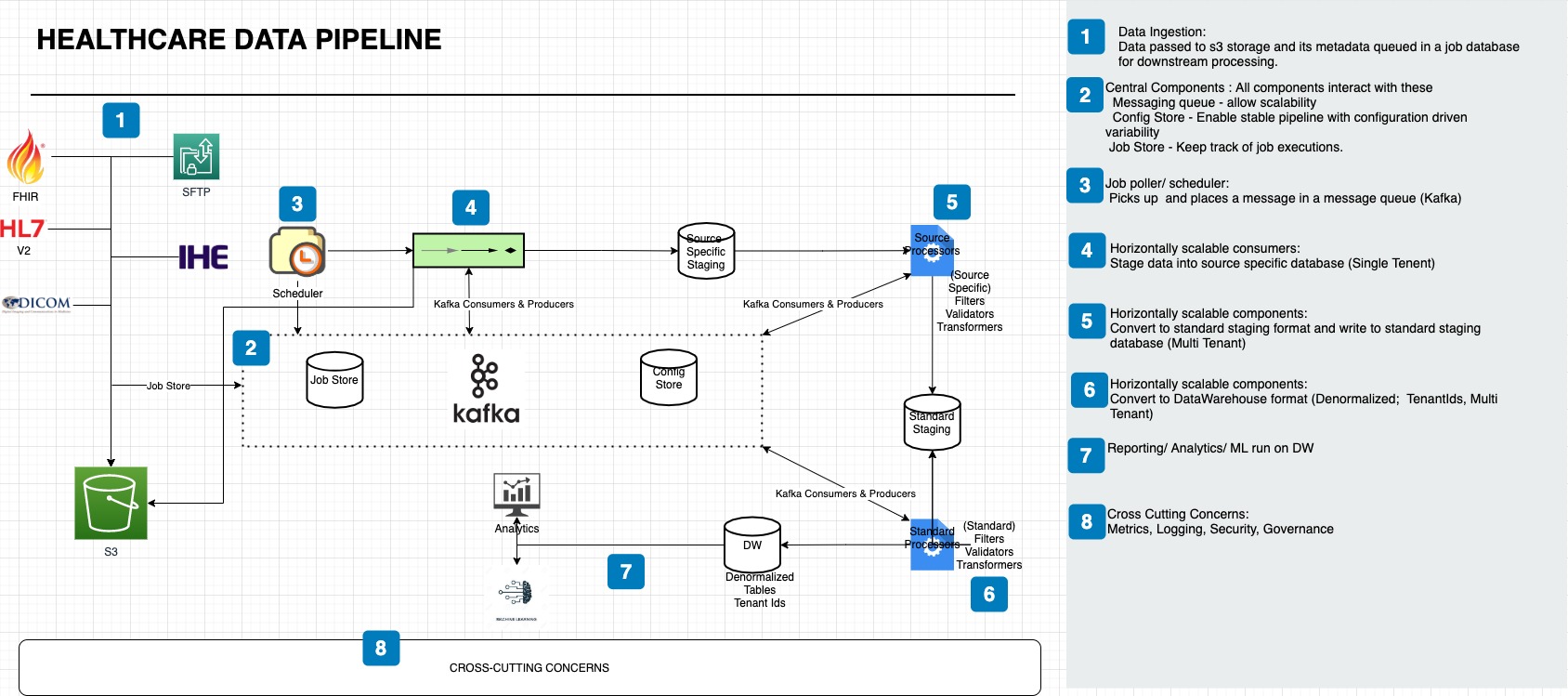
Creating stable data pipelines in healthcare can be quite challenging for a number of reasons. In this article we will review at some these challenges and propose an opinionated healthcare integration pipeline that can help mitigate them.
It is understandable that every healthcare integration project has its own niche and market. This makes it difficult to find a tried and tested methodology for creating a pipeline. However, it is still important to stick to some principles that are applicable to most situations. One such principle is to focus on standardizing the different sources of data so a single (or just a few) pipeline(s) paths can be used
Duplication/ difficult reuse
Without proper planning , data pipelines can degenerate into a mess of customizations that are difficult to reuse.
A good principle to use to prevent such a situation is to apply changes at a few defined levels consistently. For example if calculating some patient risk scores, 1st apply a general scoring logic (reusable across all sources) that is not source specific, then if needed, apply a source specific scoring that can override the general one. These levels should be maintained separately so they can evolve independently.
Reuse can also be enhanced by using configurations ideally stored in a database. The pipeline stages can query the configuration to find out which components of logic to apply to the data. This can reduce the additional pipeline changes needed with every new data source added in the future – The pipeline stays constant as configuration evolves.
Scalability Issues
A solution to scalability problems is to use an event Driven approach. Each step picks up its task from a messaging queue and also sends its results to a queue. Apache Kafka is a good option for this type of setup.
Message queues are better suited for streaming data sources (say hl7 v2 or Fhir), but they can also be used for batch loads if only the job metadata and not the message itself are put in the queue.
Using configuration driven approach mentioned above can also help avoid a ‘pipeline per data source’ anti-pattern.
Moving the Datawarehouse to cloud distributed solutions such as Redshift should also help scale.
To public cloud or not?
The concerns about using public cloud providers in healthcare are getting less with time. Healthcare data being very sensitive (see HIPAA).
Regardless , architecting pipelines based on micro-services that can be deployed in-house, in private or public cloud without a lot of changes should help with this.
Monitoring & Alerting
Pipeline Metrics and Logging are crucial when especially when using horizontally scalable solutions. It is important to be able to view say the counts of data being processed at each stage and processing node and any logs of errors from a centralized dashboard. If this is not done , it is difficult to get notified when something goes wrong.
Skills Shortage
It is difficult to find enough expertise on all the technologies needed to run a modern data pipeline. To reduce the need for specialized knowledge, use of sql based tools (see dbt) can help.
Fast Healthcare Interoperability Resources (FHIR) is a standard for exchanging healthcare information electronically. FHIR maintains healthcare domain resources representations mainly in json and xml formats.
Hapi-Fhir-Jpa (https://hapifhir.io/hapi-fhir/) is a complete implementation of the HL7 FHIR (http://hl7.org/fhir/) standard for healthcare interoperability in Java. This project provides a java/spring JPA backend with a front end to interact with resources. In the website , it states that the “recommended way to get started with the HAPI FHIR JPA server module is to begin with the starter project”. ( https://github.com/hapifhir/hapi-fhir-jpaserver-starter). Other than this recommendation, I could not find any specific guide on how to do just that in a real world production setting.
My requirements for using the project include the following:
Streamline my development/build/release process by using the jpa-starter project as an explicitly declared dependency , rather than clone the project and modify its internal structure. (Ever heard of the 12 factor app?)
Extend the project by
Use spring framework for all the functionality extensions, using java Configuration
Allowing easy addition of interceptors to extend functionality.
Demo receiving a resource and then sending a message to a Kafka topic using an interceptor.
Package the app in a runnable jar with an embedded web server. (again see https://12factor.net/processes). Running the application this way (as opposed to as a war on a web server) conforms more with microservice architecture. This allows the app to be run as an independent process that can be scaled up or shut down as needed.
Dependencies
I’ll be using gradle to manage dependencies. 1st step is to declare the dependency on the war in maven repository. Notice the ‘@war’ extension that brings in the whole war without exploding and picking the jars and classes in it.
Next, we extract the war contents so I can use its classes, lib and resources(js, css, img). There are a few exclusions here and they will have to be added in the project itself.
tasks.register("explodeHapiFhir",Copy) {
from zipTree(configurations.warOnly.singleFile)
into "lib/hapiFhirWar"
exclude 'WEB-INF/classes/logback.xml' ,
'WEB-INF/classes/hapi.properties',
'WEB-INF/classes/ca/uhn/fhir/to/FhirTesterMvcConfig.class',
'WEB-INF/classes/ca/uhn/fhir/jpa/starter/FhirTesterConfig.class'
Next, static resources are copied to current project – see example for js below (same is done for css and img directories)
tasks.register('copyJs',Copy){
from 'lib/hapiFhirWar/js'
into 'src/main/resources/js'
}
// other similar copy tasks for css, js, thymeleaf templates
compileJava {
dependsOn explodeHapiFhir
dependsOn copyJs
dependsOn copyCss
dependsOn copyImg
dependsOn copyTemplates
}
Now running ./gradlew build will copy resources to current project.
Extending
There are 2 servlets /contexts to register. One is hapi-fhir that handles requests to interact with resources, the other is the fhir-tester app that provides a ui to send requests to the 1st servlet.
Hapi-fhir-jpa uses spring web.xml configuration to register servlets. We replace that with java configuration, taking advantage of capabilities added since servlet 3.0.
public class FhirServletInitializer implements WebApplicationInitializer {
@Override
public void onStartup(ServletContext servletContext)
throws ServletException {
ServletRegistration.Dynamic dispatcher = servletContext
.addServlet("fhirServlet",
(Servlet) new HdipRestfulServer());
dispatcher.setLoadOnStartup(0);
dispatcher.addMapping("/fhir/*");
}
}
Registering the 2nd servlet using spring
public class ServletInitializer extends AbstractAnnotationConfigDispatcherServletInitializer{
@Override
protected Class<?>[] getRootConfigClasses() {
return new Class[]{
FhirServerConfigCommon.class, FhirServerConfigR4.class,
HdipConfig.class} ;
}
@Override
protected Class<?>[] getServletConfigClasses() {
return new Class[]{
FhirTesterConfig.class,
HdipMvcConfigurer.class,
};
}
@Override
protected String[] getServletMappings() {
return new String[]{"/"};
}
@Override
protected String getServletName(){
return "spring";
}
}
We use Java Configuration classes to register components such as the mvc configurer, kafka template.Showing only 1 config class below.
@Configuration
public class HdipConfig{
@Value("${topic.resourceCreated}")
private String resourceCreatedTopic;
@Value("${hdip.kafka.host}")
private String kafkaHost;
@Bean
public ResourceCreatedInterceptor resourceCreatedInterceptor(KafkaTemplate template){
return new ResourceCreatedInterceptor
(kafkaTemplate());
}
@Bean
public ProducerFactory<Long, IBaseResource> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaHost);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
return props;
}
@Bean
public KafkaTemplate<Long,IBaseResource> kafkaTemplate() {
return new KafkaTemplate<Long,IBaseResource>
(producerFactory());
}
@Bean
public KafkaAdmin admin() {
Map<String, Object> configs = new HashMap<>();
configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaHost);
return new KafkaAdmin(configs);
}
@Bean
public NewTopic resourceCreatedTopic() {
return TopicBuilder.name("resourceCreated")
.partitions(1)
.replicas(3)
.compact()
.build();
}
}
We extend the provided JpaRestfulServer so we can add listeners to it as we wish. This is a cleaner way to extend the hapi fhir project , keeping our business logic separate from the parent dependency itself.
public class HdipRestfulServer extends JpaRestfulServer {
private static final long serialVersionUID = 1L;
@SuppressWarnings("unchecked")
@Override
protected void initialize() throws ServletException {
super.initialize();
ApplicationContext context = (ApplicationContext)
getServletContext().getAttribute(
"org.springframework.web.context.WebApplicationContext.ROOT");
super.registerInterceptor(
context.getBean(ResourceCreatedInterceptor.class));
}
The interceptor listens for Patient resource created events and sends a message to a Kafka queue. This can be used by a downstream process which retrieves the resource from the server for further processing. Obviously you will need a running kafka broker.
@Interceptor
public class ResourceCreatedInterceptor {
static final Logger logger = LoggerFactory.getLogger(ResourceCreatedInterceptor.class);
private KafkaTemplate template;
public ResourceCreatedInterceptor(KafkaTemplate template){
this.template = template;
}
@Hook(Pointcut.STORAGE_PRESTORAGE_RESOURCE_CREATED)
public void handleIntercept
(IBaseResource resource, RequestDetails reqDetails,
ServletRequestDetails servletReqDetails){
if(reqDetails.getResourceName().equals("Patient")){
template.send("resourceCreated",
((Patient) resource).getIdentifierFirstRep()
.getValue() ,"Patient");
template.flush();
logger.info("Resource Created: "+ resource);
}
}
}
Now you can navigate to the Patient link, paste a Patient resource and click create. If you have way to view kafka messages (I use kafdrop), you can see the messages queued up in the kafka topic.
And that’s it folks. The source code can be found in github here